The short version
Semantic similarity beats exact matching - Redis-based semantic caches achieve 61-69% hit rates with positive hit rates exceeding 97%
- Multi-tier caching changes the economics - Combining semantic caching, prefix caching, and full inference can reduce costs by 80% or more versus naive implementation
- Cache invalidation is simpler than its reputation - Time-based expiration handles most cases, with content-triggered updates for the rest
Also in the Claude cost series:
- Claude.ai web app costs - chat interface (Pro/Max users)
- Claude Code subscription costs - terminal (Max 20x users)
- Claude API costs - pay-per-token developers
- Multi-model AI strategies - cross-vendor architecture
Each tackles a different surface. Read the one that matches how you actually use Claude.
The LLM API bill doubled last month. Again.
You added caching weeks ago. It barely moved the needle. The frustrating part isn’t that caching failed. It’s that you probably cached the wrong thing. This is one of many operational surprises covered in the broader LLMOps discipline. Most teams cache responses when they should be caching prompts. The economics are totally different, and it’s an easy mistake to make when you’re building fast.
The wrong kind of caching costs you twice
When I talk to teams struggling with LLM costs, they’ve basically built some version of response caching. User asks a question, you hash it, check if you’ve seen it before, serve the cached answer. Logical, right?
Wrong optimization.
Exact question matching gives you terrible hit rates. Someone asks “How do I reset my password?” You cache the response. Next person asks “What’s the password reset process?” Different hash, cache miss, full API call. If you’re lucky, you’re seeing around 30% hit rate.
Recent research on semantic caching shows how often LLM queries are similar enough to reuse, meaning you’re reprocessing the same context repeatedly. The painful part isn’t generating the answer. It’s the model processing your system instructions, reference documents, and context every single time. That’s what you should cache.
How semantic caching actually works
Instead of exact string matching, semantic caching uses embeddings to find similar prompts.
A query comes in. Convert it to an embedding. Search your cache for similar embeddings. If you find a match above your threshold, usually 0.85 to 0.95 cosine similarity, that’s a hit. The model has already processed similar context, so you reuse that work.
GPTCache pioneered this approach as an open-source tool, integrating with LangChain and LlamaIndex. It has real limitations though. The default SQLite backend struggles in production, and its default 0.8 similarity threshold doesn’t generalize well across different use cases. Newer options like GenerativeCache run about 9x faster and vary thresholds for different content types. MeanCache adds privacy-preserving federated learning and produces fewer false hits.
You need three things to implement this: an embedding model to convert queries to vectors, a vector store to search those embeddings fast, and a threshold to decide what counts as similar enough. Redis-based semantic caching can reduce API calls by up to 68.8%, with hit rates of 61-69% and positive hit rates exceeding 97%. Hard to argue with those numbers.
If you want to skip the trial-and-error and get to working, Blue Sheen runs these engagements.
The numbers that get budget approved
Without caching, every API call processes your full prompt. System instructions, reference docs, conversation history. Full price every time.

Anthropic reports that prompt caching cuts cost by up to 90% and latency by up to 85% for long prompts. OpenAI now offers automatic caching enabled by default, cutting cached input costs with no code changes required. There’s a small premium to write to cache, but far less to read it back. (Update, June 2026: prompt caching on the Claude API is generally available now, no beta header. The default cache lives 5 minutes; you can opt into a 1-hour window. Cache reads still cost a small fraction of base input, so the math below holds.)
The current Claude pricing breakdown makes the math obvious:
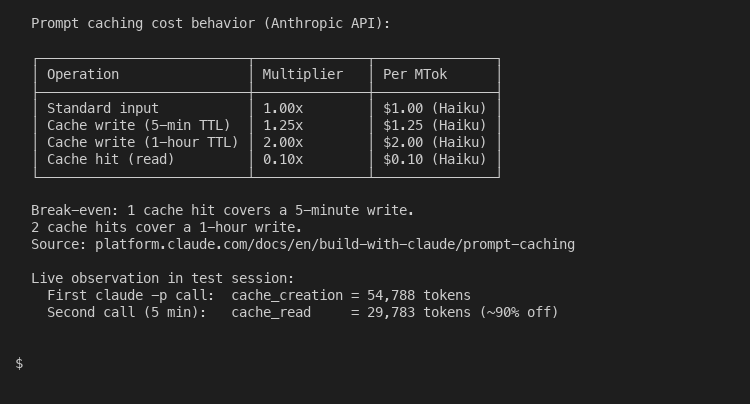
A 5-minute cache write costs 25 percent more than a standard input token. A cache hit costs 10 percent of the standard rate. Break-even arrives after a single cache read on the 5-minute TTL. After that, every reuse is pure savings against the standard rate. The 1-hour TTL doubles the write cost in exchange for a longer window, which pays back after two reads.
Think about a typical RAG application. You’ve got system instructions, reference documents, maybe some examples. That’s your static context. Same for every query. Cache it once, reuse it hundreds of times. The current recommended approach is multi-tier: semantic cache first, then prefix cache, then full inference. Combined savings can exceed 80% versus naive implementation.
Character.ai demonstrated this at scale. They built caching into their infrastructure and scaled to 30,000 messages per second. Their approach wasn’t exotic optimization. Turns out, most prompts share a large fraction of their content. A chat application with stable system prompts, consistent document retrieval, and repetitive user questions can cache 70% or more of input tokens through prefix caching while semantic caching handles 30% of queries outright. Commercial solutions like Portkey offer caching as a managed gateway feature. For RAG applications, hit rates range from 18-60% depending on the workload.
Cache invalidation without the drama
Everyone quotes Phil Karlton’s “two hard problems in computer science” joke when cache invalidation comes up. For LLM caching, it’s probably simpler than you’d expect.
Most cached responses do fine with time-based expiration. Set a reasonable TTL. Maybe 5 minutes for rapidly changing data, an hour for stable content. TTL-based freshness works well for stable contexts like documentation or reference material, though it falls short for rapidly changing data.
For content that changes on events rather than time, you need content-triggered invalidation. Document gets updated? Clear cache entries referencing it. Model version changes? Flush and restart. The open challenges in this space center on adapting the cache online as query patterns shift, not just training it offline.
Monitor your hit rates and adjust thresholds. Start conservative. 0.90 similarity for a hit. Too many misses? Lower it to 0.85. Complaints about irrelevant responses? Raise it back to 0.95. Tools like GenerativeCache vary thresholds for different content types automatically, but manual tuning works fine at first. Treat your cache layer as part of prompt management - the prompt versioning, the cache TTLs, and the embedding thresholds are one connected system.
Where to start this week
Does one caching layer solve everything? No. The teams seeing real results use multi-tier approaches. Exact matching for identical queries, semantic matching for similar questions, fall back to full API calls when nothing matches. Cloud providers have caught on. Microsoft offers Azure Cosmos DB for semantic caching, Google has Vertex AI with Vector Search, and AWS provides Titan embedding with MemoryDB.
Track the right metrics. Cache hit rate monitoring matters, but cost per query and user-perceived latency matter just as much. Helicone, which has processed over 2 billion LLM interactions, reports that built-in caching typically reduces API costs by 20-30%. Their proxy-based integration adds only 50-80ms average latency.
Don’t try to cache everything. Some queries are unique. Some contexts change so fast that caching adds complexity without benefit. The teams doing this well identify their repetitive traffic. Many LLM queries are semantically similar. Focus there first.
Pick your highest-volume endpoint. Add semantic caching. Measure for a week. The pattern becomes obvious fast.
Prompt caching is the highest ROI optimization for most LLM applications. Not prompt engineering, not model fine-tuning, not switching providers. Just caching what you’re already sending anyway. The infrastructure is mature. Every major provider now offers some form of caching, from Anthropic’s prompt caching to OpenAI’s automatic, zero-config caching. Most teams leave this money on the table not because it’s hard, but because they’re caching the wrong thing.





